Arm KleidiAI 助力提升 PyTorch 上 LLM 推理性能

作者:Arm 基础设施事业部软件工程师 Nobel Chowdary Mandepudi
本文引用地址://www.cghlg.com/article/202412/465428.htm生成式人工智能 (AI) 正在科技领域发挥关键作用,许多企业已经开始将大语言模型 (LLM) 集成到云端和边缘侧的应用中。生成式 AI 的引入也使得许多框架和库得以发展。其中,PyTorch 作为热门的深度学习框架尤为突出,许多企业均会选择其作为开发 AI 应用的库。通过部署 Arm Kleidi 技术 ,Arm 正在努力优化 PyTorch,以加速在基于 Arm 架构的处理器上运行 LLM 的性能。Arm 通过将 Kleidi 技术直接集成到 PyTorch 中,简化了开发者访问该技术的方式。
在本文中,我们将通过一个演示应用来展示 Arm KleidiAI 在 PyTorch 上运行 LLM 实现的性能提升。该演示应用在基于 Arm Neoverse V2 的亚马逊云科技 (AWS) Graviton4 R8g.4xlarge EC2 实例上运行 Llama 3.1。如果你感兴趣,可以使用以下 Learning Path,自行重现这个演示。 (Link: https://learn.arm.com/learning-paths/servers-and-cloud-computing/pytorch-llama)
演示应用
我们的演示应用是一个基于 LLM 的聊天机器人,可以回答用户提出的各种问题。该演示使用 Arm 平台上的 PyTorch 框架运行 Meta Llama 3.1 模型,并被设计成一个使用 Streamlit 前端的浏览器应用。Streamlit 将信息提供给 Torchat 框架,后者运行 PyTorch 并作为 LLM 后端。Torchat 输出的信息进入注意力层并生成词元 (token)。这些词元使用 OpenAI 框架流式传输功能发送到前端,并在浏览器应用上显示给用户。该演示的架构下图所示。
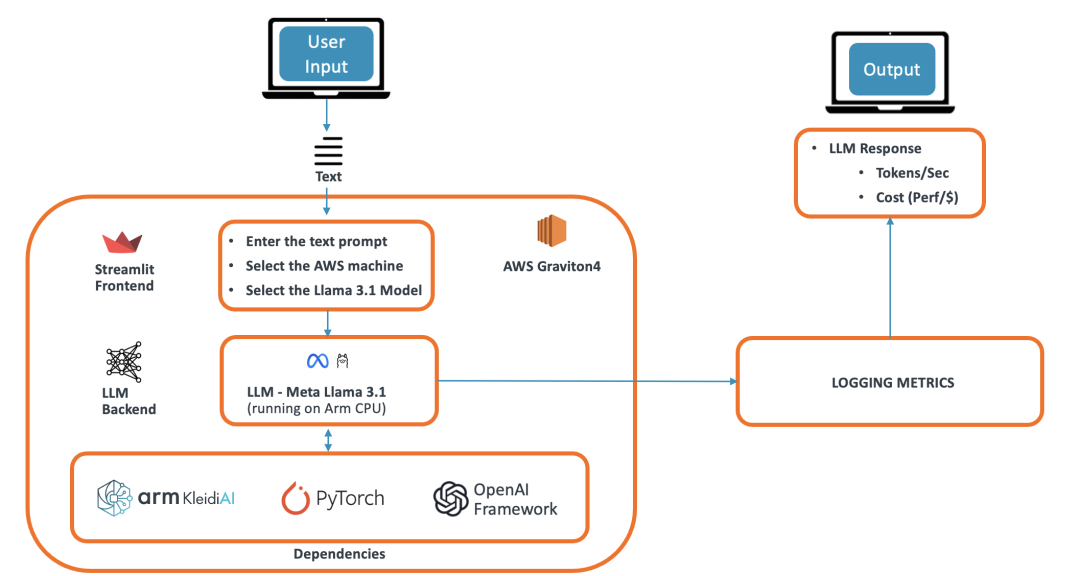
图:演示架构
演示应用在 LLM 推理结束后测定并显示以下性能指标:

生成首个词元的用时(秒) :对于 LLM 推理,需要快速生成首个词元,以尽量减少延迟并向用户提供即时输出。

解码速度/文本生成(词元/秒) :每秒词元数是指生成式 AI 模型生成词元的速率。生成下一个词元的时间最长不超过 100 毫秒,这是交互式聊天机器人的行业标准。这意味着解码速度至少为 10 个词元/秒。这对于提升实时应用的用户体验至关重要。

生成百万词元的成本(美元) :根据 AWS 云端 EC2 实例的解码速度和每小时成本,我们可以计算出生成 100 万个词元的成本,这也是一个常用的比较指标。由于每小时成本是固定的,解码速度越快,生成百万词元的成本就越低。

生成提示词的总用时(秒) :这是使用所有词元生成提示词所花费的总时间。

生成提示词的总成本(美元) :这是根据使用所有词元生成完整提示词的总时间、解码速度和云端机器成本计算得出的。
下图显示了示例响应,可作为使用所示指标验证聊天机器人的示例。生成首个词元的时间短于 1 秒,解码速率为 33 个词元/秒,这两项数据都非常令人满意,并且满足交互式聊天机器人的行业标准。
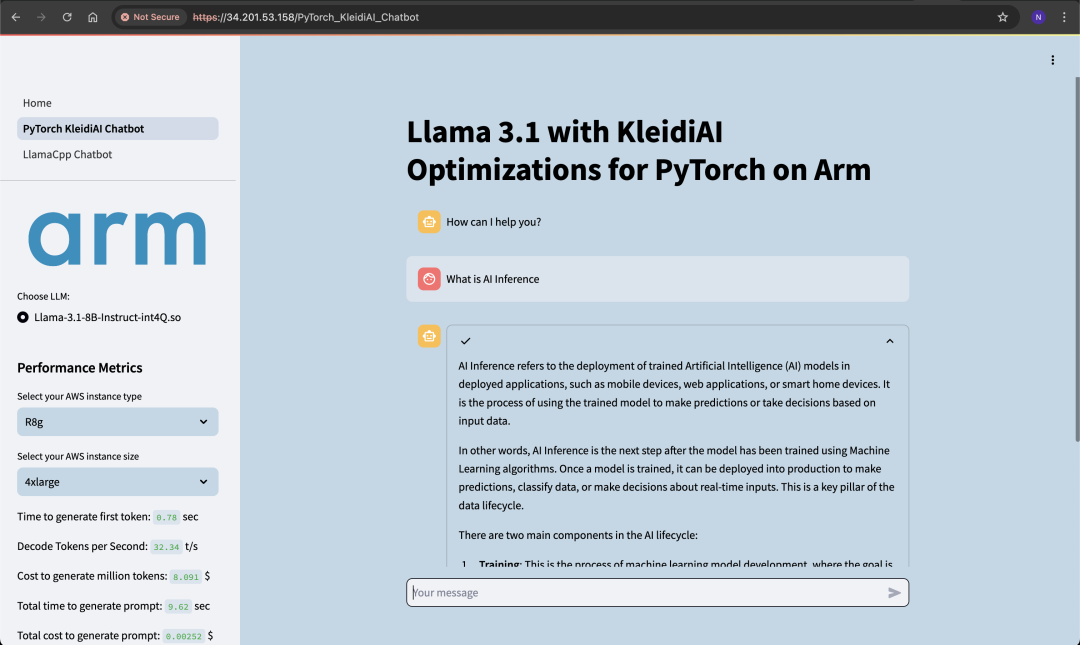
图:包含示例响应和指标的演示
针对 PyTorch 的 KleidiAI 优化
KleidiAI 库为 Arm 平台提供了多项优化。Kleidi 在 Torch ATen 层中提供了一个新算子以加载模型。该层将模型权重以特定格式打包在内存中,使得 KleidiAI GEMM 内核可用来提高性能。同样地,针对模型执行的优化使用了 ATen 层中的另一个算子。该算子对先前打包的模型权重进行 matmul 运算的量化。
在我们的演示中,该模型是从 Meta Hugging Face 库下载的。该模型使用 INT4 内核布局打包在内存中,然后使用针对 PyTorch 优化的 INT4 KleidiAI 内核进行量化。该演示的架构如下图所示。
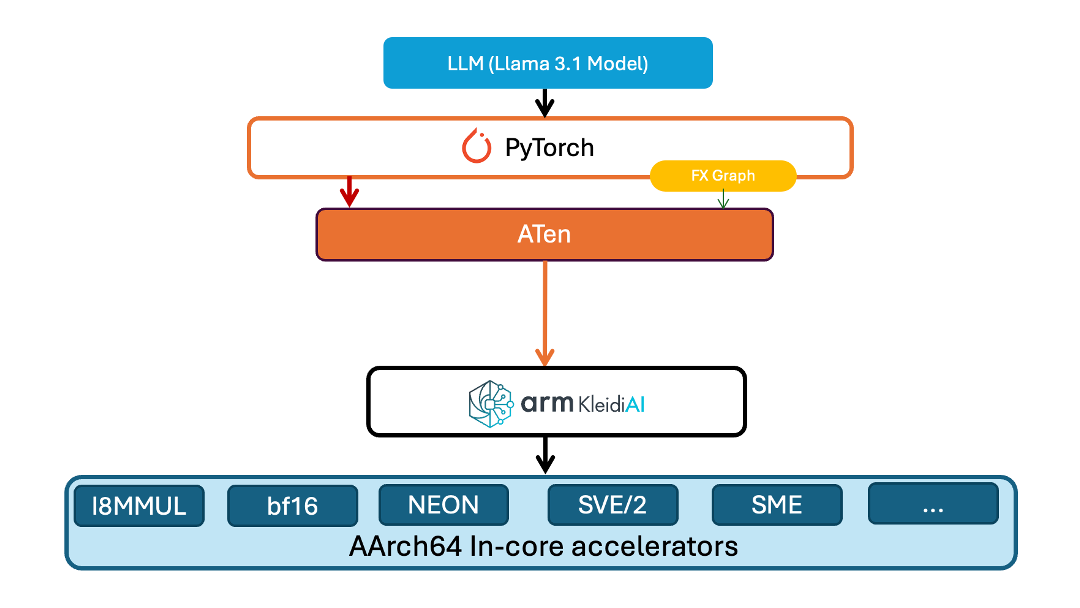
图:针对 PyTorch 实现的 KleidiAI 优化
使用我们 Learning Path 中包含的补丁 [注] ,可将这些 KleidiAI 优化应用到 PyTorch、Torchchat 和 Torchao 中。你可以使用这些补丁来查看 Arm 平台上的 PyTorch 为工作负载带来的 LLM 推理性能提升。
注: Arm KleidiAI 的 PyTorch 补丁正在与上游 PyTorch 合并,并将在未来的 PyTorch 官方版本中提供。
性能
为了印证 KleidiAI 的性能优势,我们使用 PyTorch 运行相同的聊天机器人应用,并测定了 KleidiAI 优化前后的每秒生成词元数和生成首个词元的用时,结果如下图所示。
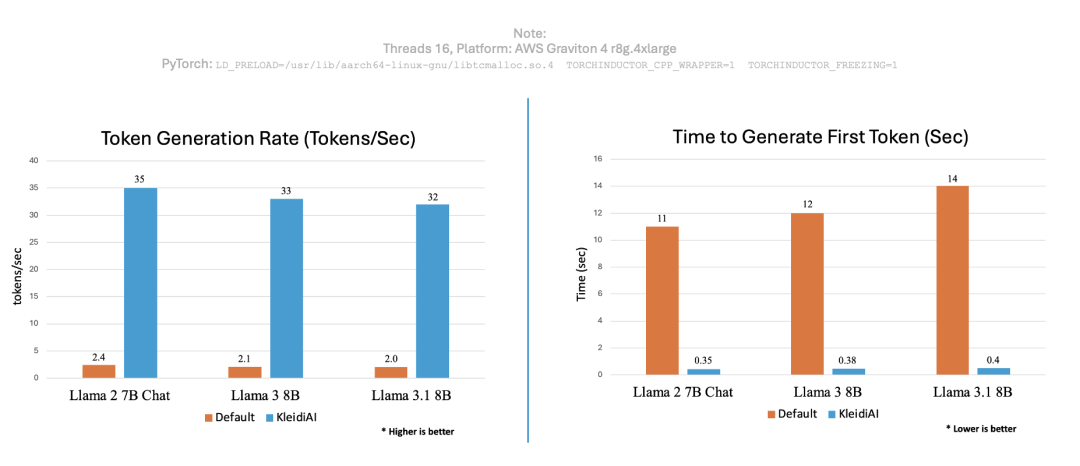
图:性能比较
可以看到,将 KleidiAI 库应用到现有的生成式 AI 技术栈中可以大大提高词元生成速率,并缩短为不同生成式 AI 模型生成首个词元的时间。
结论
对于聊天机器人等实时工作负载来说,在 CPU 上运行 LLM 推理可行且有效。我们在之前 《在基于 Arm Neoverse 的 AWS Graviton3 CPU 上实现出色性能》 文章中使用 Llama.cpp 演示了这一点。在本文中,我们展示了如何使用 KleidiAI 库为 Arm 平台上的 PyTorch 实现良好的 LLM 推理性能。通过使用搭载 Neoverse V2 核心且基于 AWS Graviton4 的 R8g 实例进行演示,印证了 KleidiAI 为在 Arm 平台上使用 PyTorch 运行 LLM 推理实现了显著的性能提升。开发者现在可以利用 Arm 针对 PyTorch 的 KleidiAI 优化来运行新的或现有的 AI 应用。







评论